
Thu thập dữ liệu qua toàn bộ một website (tiếp tục)
Bằng cách điều chỉnh code crawling cơ bản, bạn có thể tạo một chương trình crawler/thu thập dữ liệu kết hợp
(hay ít nhất in ra dữ liệu)
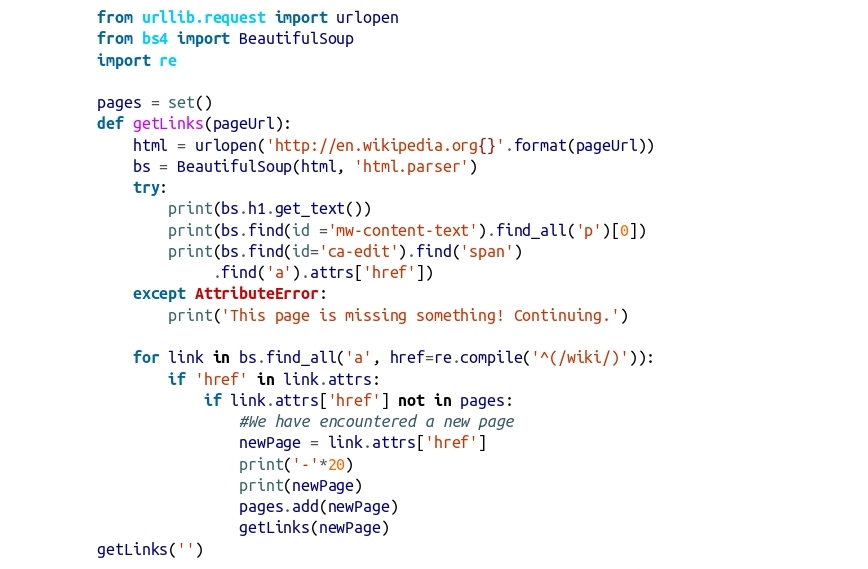
For loop trong chương trình này là cơ bản tương tự như nó đã là trong chương trình crawling gốc (với thêm
vào printed dashes cho rõ ràng, chia tách nội dung được in).
Vì bạn có thể không bao giờ hoàn toàn đảm bảo rằng tất cả dữ liệu là có trên mỗi trang, mỗi phát biểu print được
xắp sếp trong trật tự cái nó là có khả năng nhất xuất hiện trên site. Đó là, h1 title tag xuất hiện trong
mọi trang, nên bạn thử nhận dữ liệu đó đầu tiên. Nội dung text xuất hiện trên hầu hết các trang (ngoại trừ các
file pages), để rằng nó là đoạn dữ liệu thứ hai để giành. Nút Edit xuất hiện chỉ trên các trang trong đó cả title
và nội dung text đã tồn tại, nhưng nó không xuất hiện trên tất cả các trang đó.
Các mô hình khác nhau cho các nhu cầu khác nhau
Rõ ràng là, một vài nguy cơ liên quan đến gói nhiều dòng trong một cái xử lí ngoại lệ. Bạn không thể thông báo
dòng nào ném ra ngoại lệ, cho một thứ. Cũng là, nếu vì một vài lí do một page chứa nút Edit nhưng không có title,
nút Edit sẽ không bao giờ được ghi lại. Tuy nhiên, nó là đủ cho nhiều trường hợp trong đó có một trật tự cacsk khả
năng của các vật xuất hiện trên site, và vô tình bỏ qua một vài điểm dữ liệu hay giữ các logs chi tiết không phải
là một vấn đề.