
Hugging Face (tiếp tục)
Trong khi hầu hết mô hình ngôn ngữ lớn hiện đại chủ yếu được huấn luyện cho khởi sinh text, chúng có thể du nhập
để thực hiện các nhiệm vụ khác qua tinh chỉnh hay học trong bối cảnh.
Nhớ lại ví dụ xem trong phần “Influencing the Model’s Response with In-Context Learning,” trong học phần đầu,
nơi bạn sử dụng học trong bối cảnh để phân hạng các câu dựa trên tình cảm chúng truyền tải. Nói cách khác, bạn
sử dụng một mô hình tạo sinh text để thực hiện các nhiệm vụ phân hạng text.
Bằng cách thao tác xử lí các cái lọc trên cạnh tay trái, danh sách các models bên phải, như mô tả trong ảnh trên,
cập nhật động để trình bày chỉ các models đó cái căn chỉnh với tiêu chí chỉ ra.
Khi click một model, chúng ta được chuyển hướng tới profile page của nó, nơi tất cả thông tin có sẵn về model
được hiển thị.
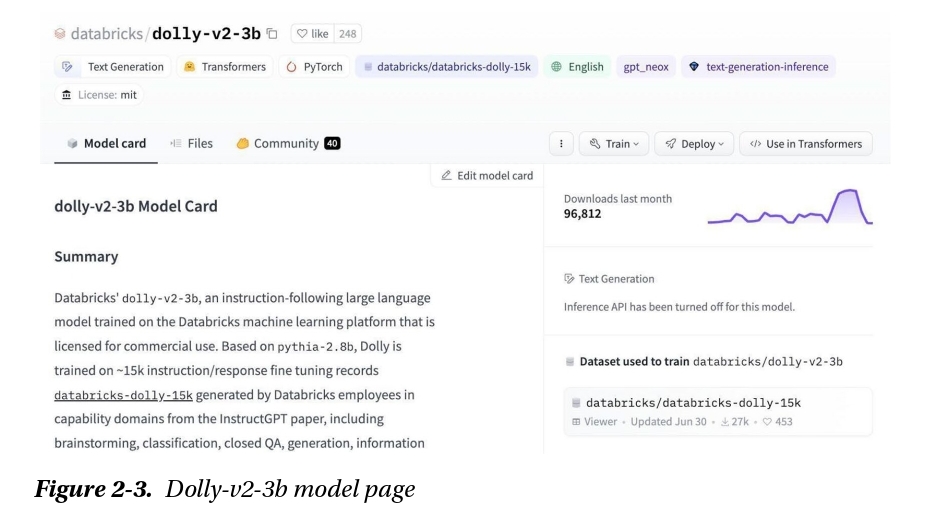
Tại đỉnh của model profile page, chúng ta tìm thấy thông tin về task cho nó nó được huấn luyện, các thư viện
tương thích, các ngôn ngữ, các tập dữ liệu sử dụng cho huấn luyện, và các điều khoản giấy phép. Nói cách khác,
tất cả dữ liệu chúng ta lọc trước kia.
Trên cạnh trái, dưới phần Model Card, thông tin có thể khác nhau đáng kể phụ thuộc vào người tạo model. Một
vài có thể bao gồm một mô tả ngắn, trong khi những cái khác có thể cung cấp các ví dụ sử dụng hay các chi
tiết về model được huấn luyện như thế nào.
Các nút nằm ở phải trên của màn hình là then chốt, đặc biệt nút “Use in Transformers”. Từ đó, chúng ta có
thể copy code cần thiết để download và sử dụng model trong môi trường phát triển của chúng ta.