
Scrape nhiều trang (tiếp tục)
Ở đây, chúng ta đơn giản đã sử dụng trường sitemap_rules mặc định để chỉ ra một lối vào, nơi chúng ta hướng dẫn
Scrapy gọi phương thức parse_product cho mỗi URL cái khớp regular expression /products/ của chúng ta.
Bạn có thể chạy spider này với lệnh sau để scrape tất cả products và xuất khẩu kết quả ra một CSV file:
scrapy runspider sitemap_spider.py -o output.csv
Bây giờ cái gì xảy ra nếu website không có sitemap? Lại một lần nữa, Scrapy có một giải pháp cho cái này!
Hãy để tôi giới thiệu bạn tới CrawlSpider.
Chính như spider gốc của chúng ta, CrawlSpider sẽ crawl website mục tiêu bằng cách bắt đầu với một list start_urls.
Sau đó cho mỗi url, nó sẽ rút tất cả các links dựa trên một danh sách các Rules. Trong trường hợp của chúng
ta, nó là dễ, các products có cùng mô hình URL /products/product_title nên chúng ta chỉ cần lọc những URLs này.
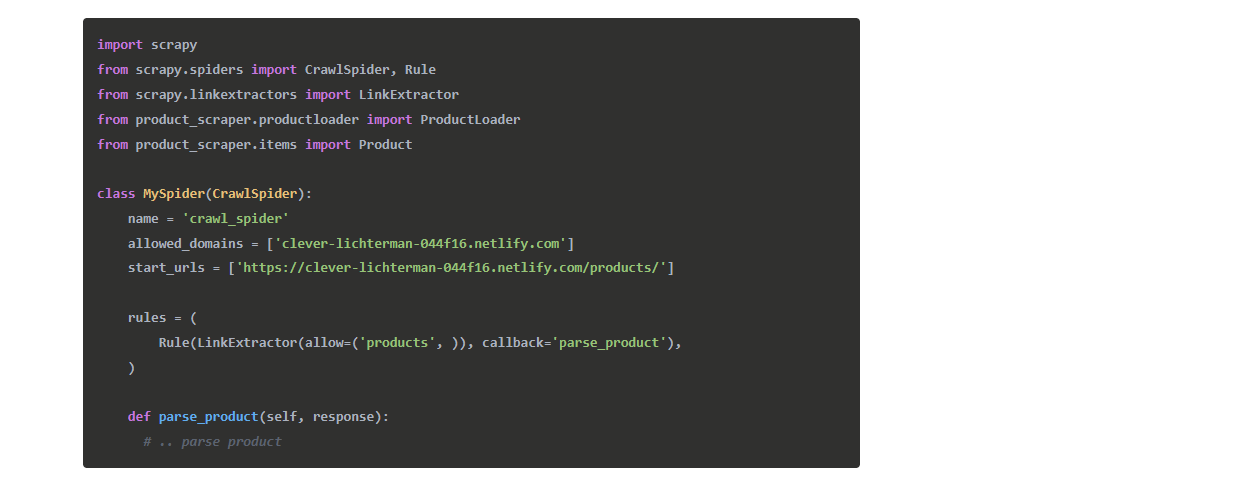
Như bạn có thể thấy, tất cả các Spiders tích hợp này là thực sự dễ để dùng. Nó sẽ là phức tạp hơn nhiều nếu làm nó
từ đầu.
Với Scrapy bạn không phải nghĩ về crawling logic, như thêm URLs mới vào một hàng đợi, theo dấu các URLs đã duyệt
xong, multi-threading…
Một thứ để vẫn giữ trong đầu là các hạn chế tốc độ và phát hiện bot. Nhiều site sử dụng các đặc tính như vậy để
chủ động dừng các scrapers khỏi truy cập dữ liệu của họ.
Kết luận
Trong post này, chúng ta đã thấy một bao quát chung về làm cách nào scrape web với Scrapy và làm cách nào nó có
thể giải quyết các thách thức web scraping phổ biến nhất của bạn. Tất nhiên, chúng ta chỉ chạm bề mặt và có nhiều
thứ thú vị hơn để khám phá, như middlewares, exporters, extensions, pipelines!
Nếu bạn làm web scraping thủ công hơn với các công cụ như BeautifulSoup / Requests, nó là dễ để hiểu Scrapy có
thể giúp tiết kiệm thời gian và xây dựng các scrapers duy trì hơn như thế nào. Tôi hi vọng bạn thích tut Scrapy
này và rằng nó sẽ thúc đẩy bạn trải nghiệm với nó.
Để đọc xa hơn không lưỡng lự nhìn vào great Scrapy documentation.