Chọn Model (tiếp tục)
Các xem xét độ trễ và phí tổn thường cung cấp thông tin cho các quy mô trong các triển khai thế giới
thực. Các models lớn phân phát hiệu suất cao nhưng là đắt đỏ để chạy và có thể sinh ra các trì hoãn
trả lời. Trong các trường hợp nơi cái đó là không thể bảo vệ, các models nhỏ hơn hay các phiên bản
nén của các models lớn hơn cung cấp một cân bằng tốt hơn. Nhiều nhà phát triển du nhập các chiến lược
lai, nơi một model mạnh mẽ xử lí các truy vấn phức tạp nhất và một model nhẹ xử lí các nhiệm vụ
theo thông lộ. Trong một vài hệ thống, định tuyến model động đảm bảo rằng mỗi yêu cầu được đánh giá
và định tuyến tới model phù hợp nhất dựa trên độ phức tạp hay khẩn trương – làm các hệ thống có thể
tối ưu hóa cả phí tổn và chất lượng.
The Center for Research on Foundation Models tại đại học Stanford đã phát hành Holistic Evaluation
of Language Models, cung cấp đo lường hiệu suất bên thứ ba khắt khe qua một phạm vi rộng các models.
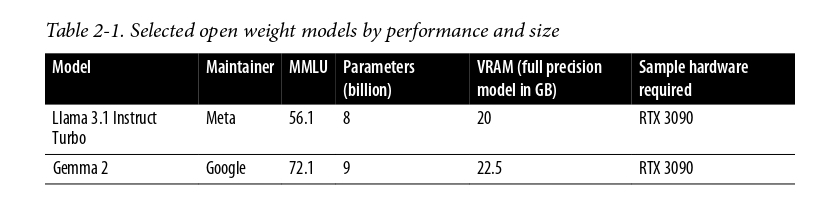
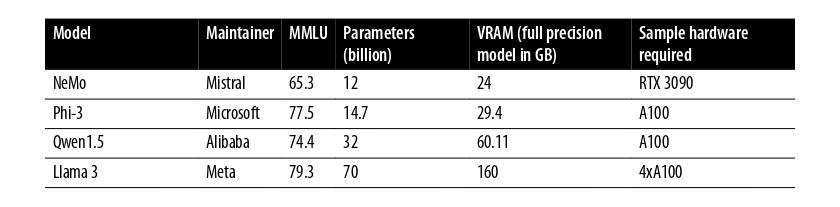
Trong bảng dưới, một lựa chọn nhỏ các mô hình ngôn ngữ được thể hiện cùng với hiệu suất của chúng trên
tiêu chuẩn Massive Multitask Language Understanding (MMLU), một đánh giá chung sử dụng phổ biến về
các khả năng của model. Các đo lường này là không hoàn hảo, nhưng chúng cung cấp cho chúng ta với một
thước đo phổ biến với nó để so sánh hiệu suất. Nói chung, chúng ta thấy rằng các models lớn hơn thực
hiện tốt hơn, nhưng không ổn định (một vài models thực hiện tốt hơn kích cỡ của chúng cho là). Quan
trọng là, các tài nguyên điện toán nhiều hơn được yêu cầu để thu về hiệu suất cao.