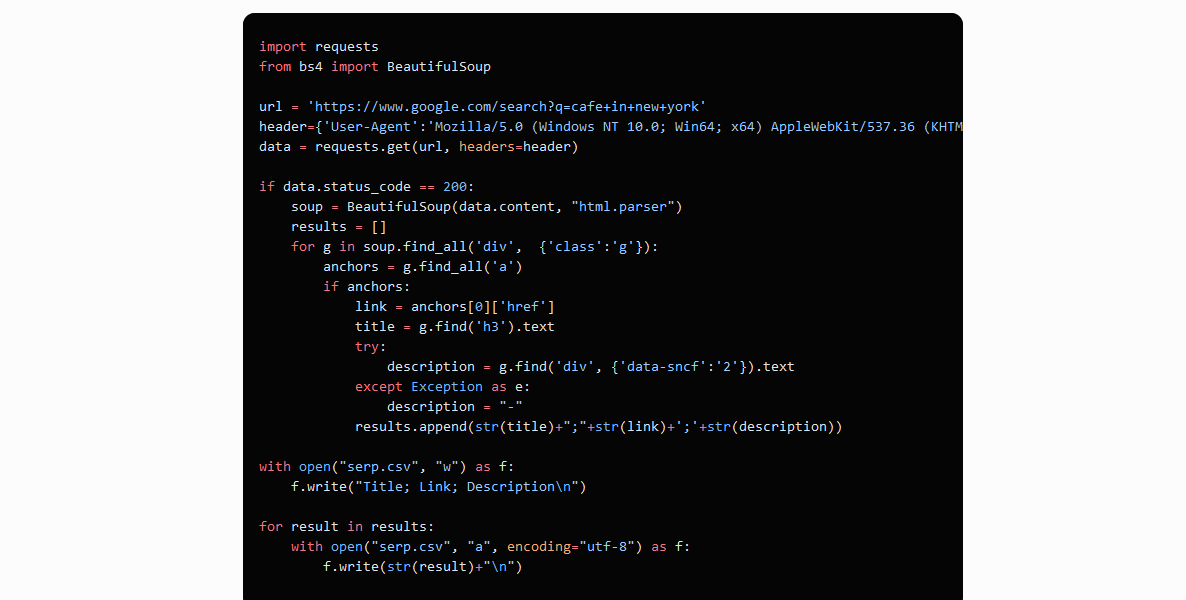
Scrape tìm kiếm Google với Python sử dụng BeautifulSoup
Bây giờ rằng chúng ta đã thiết lập môi trường phát triển hãy đào sâu vào quá trình duyệt và rút dữ liệu từ
các kết quả tìm kiếm Google. Chúng ta sẽ sử dụng thư viện requests để gửi các yêu cầu HTTP và giành trả lời
HTML, cùng với thư viện BeautifulSoup để duyệt và điều hướng cấu trúc HTML. Hãy tạo một file mới và kết
nối các thư viện:
import requests
from bs4 import BeautifulSoup
Để giả trang scraper của chúng ta và giảm khả năng bị phong tỏa, hãy thiết lập các headers truy vấn:
header={‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36′}
Nó là mong muốn để chỉ ra trong yêu cầu các headings hiện có. Ví dụ, bạn có thể sử dụng cái của bản thân
bạn, cái có thể được tìm thấy trong DevTools trên Network tab. Sau đó, chúng ta thực thi truy vấn và viết
trả lời vào một biến:
data = requests.get(‘https://www.google.com/search?q=cafe+in+new+york’, headers=header)
Tại giai đoạn này, chúng ta đã nhận code của page, và sau đó chúng ta phải xử lí nó. Tạo một BeautifulSoup
object và duyệt HTML code kết quả của trang:
soup = BeautifulSoup(data.content, “html.parser”)
Hãy cũng tạo một biến results trong đó chúng ta sẽ viết dữ liệu về các phần tử:
results = []
Để rằng chúng ta có thể xử lí phần tử dữ liệu theo phần tử, nhớ lại là mỗi phần tử có một class ‘g’. Đó là, để
đi qua tất cả các phần tử và nhận dữ liệu từ chúng, nhận tất cả các phần tử với class ‘g’ và đi qua chúng
từng cái một, nhận dữ liệu cần thiết. Để làm cái này, hãy tạo một for loop:
for g in soup.find_all(‘div’, {‘class’:’g’}):
Cũng là, nếu chúng ta nhìn gần vào page code, chúng ta thấy rằng tất cả các phần tử là con của tag <a>, cái
lưu giữ page link. Hãy sử dụng cái đó và nhận dữ liệu title, link và description. Chúng ta sẽ xem xét rằng
description có thể là rỗng và đặt nó vào khối try…except:
if anchors:
link = anchors[0][‘href’]
title = g.find(‘h3’).text
try:description = g.find(‘div’, {‘data-sncf’:’2′}).text
except Exception as e:
description = “-“
Đặt dữ liệu về các phần tử trong biến results:
results.append(str(title)+”;”+str(link)+’;’+str(description))
Bây giờ chúng ta có thể hiển thị biến trên màn hình, nhưng hãy phức tạp hóa các thứ và lưu dữ liệu vào một
file. Để làm cái này, tạo hay ghi đè một file với các cột “Title”, “Link”, “Description”:
for result in results:
with open(“serp.csv”, “a”, encoding=”utf-8″) as f:
f.write(str(result)+”\n”)
Hiện tại, chúng ta có một scraper bộ máy tìm kiếm đơn giản cái thu thập các kết quả trong một CSV file:

Code đầy đủ: