Chọn Model (tiếp tục)
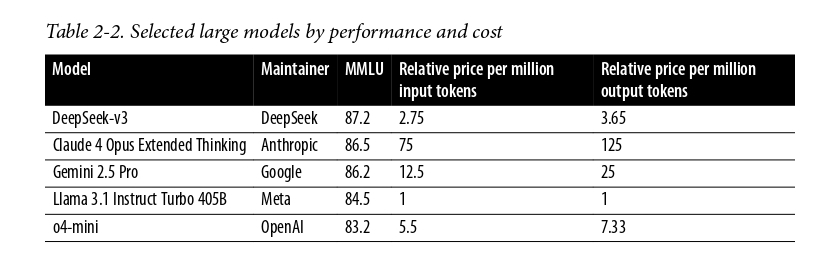
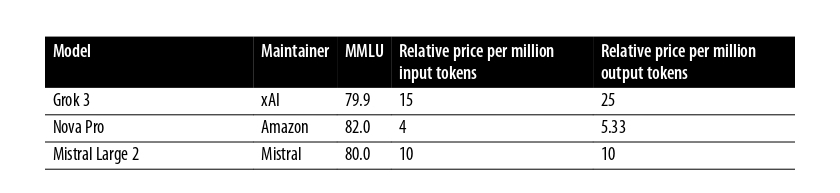
Bây giờ hãy nhìn vào một vài models flagship lớn. Chú ý rằng 2 trong số models này, DeepSeek-v3 và
Llama 3.1 Instruct Turbo 405B, đã được phát hành như các models nặng mở nhưng những cái khác vẫn chưa.
Cái đó nói, các models lớn này điển hình yêu cầu ít nhất 12 GPUs cho hiệu suất hợp lí, nhưng chúng có
thể yêu cầu nhiều hơn. Các models lớn này hầu như luôn được sử dụng trên các máy chủ trong các trung
tâm dữ liệu lớn. Điển hình thì, các huấn luyện viên model đòi phí cho truy cập tới các models này dựa
trên số tokens đầu vào và đầu ra. Lợi thế của cái này là rằng các nhà phát triển không cần lo lắng
về máy chủ và sử dụng GPU nhưng có thể bắt đàu xây dựng ngay bây giờ. Bảng dưới thể hiện các chi phí và
hiệu suất model trên cùng tiêu chuẩn MMLU.